I came across a situation that ordinarily should have been "impossible" (with standard physical HBAs), but as NetApp uses software coded HBA WWPNs, I was faced with duplicate WWPNs on a C-DOT HA pair of nodes.
First, it is necessary to understand how Data ONTAP generates WWPNs for physical and virtual adapters. When a system is initialised, a system node name is generated for either one or both nodes, depending on whether single-image mode is configured or not.
7-mode WWPN Allocation
In 7-mode ONTAP, Single Image mode was used in order to logically address a HA-pair as a single target FC entity. Essentially, a pair of nodes share a single WWNN (node name), with FC adapters subsequently assigned a WWPN based on the WWNN.

As you can see here, the 4th octet distinguishes an individual adapter on the node
The 5th Octet distinguishes node A from Node B.
For both nodes however, the WWNN remains the same, to facilitate correct MPIO behavior.
The other octets in the WWPNs precisely match thesingle-image WWNN assigned to the HA Pair
C-DOT WWPN Allocation
Each node is allocated a separate WWNN. I understand this is done in the "factory" before the nodes are shipped to the end customer.
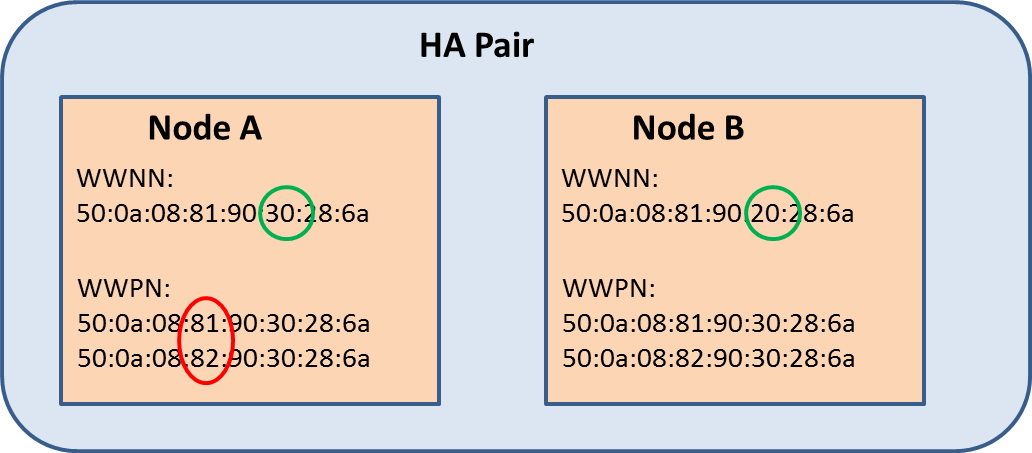
Each physical node is distinguished by the 6th octet only.
The WWPNs for each adapter on each node are then derived from the node's WWNN using the 4th octet to distinguish between different physical ports.
vServer NPIV address allocation seems to follow a completely different format for generating the WWPNs, the WWNN for the data vServer for the above example was 20:00:00:a1:98:56:52:74
Duplicate WWPNs
In my situation, a system had been factory initialised using single-image style WWNN allocation. I'm told this was a once-off manufacturing error, however I can see how you could potentially reproduce this issue yourself when reinitialising a system (although I didn't have sufficient spare time to reinitialise the system and test this theory).
As the WWPNs are derived from the WWNN, using sequential increments of the 4th octet, if the WWNNs are the same on each node, the WWPNs will also be the same.
We noticed this issue when the fabric login failed for the duplicate WWPNs on the switch ports.
Solution
Delete the configuration file from both storage controllers to force a regeneration of WWNNs. On each node in the HA pair, do the following:
Enable metadata access from dblade shell
CLUSTER01::> node run CLUSTER01-01
CLUSTER01-01> priv set diag
CLUSTER01-01*> setflag wafl_metadata_visible 1
(Force the WWNN generation by removing the configuration)
CLUSTER01-01*> rm /metadir/vdisk/configuration
CLUSTER01-01*> <CTRL-D>
CLUSTER01::> node run CLUSTER01-01
CLUSTER01-02> priv set diag
CLUSTER01-02*> setflag wafl_metadata_visible 1
(Force the WWNN generation by removing the configuration)
CLUSTER01-02*> rm /metadir/vdisk/configuration
Reboot (takeover/giveback) of each node in the HA pair
CLUSTER01::> storage failover takeover –ofnode CLUSTER01-01
CLUSTER01::> storage failover giveback –ofnode CLUSTER01-01
CLUSTER01::> storage failover takeover –ofnode CLUSTER01-02
CLUSTER01::> storage failover giveback –ofnode CLUSTER01-02
After this, node A and Node B had unique WWNNs, which then had the flow-on effect of generating unique WWPNs as was the expected behaviour.